
- Что нужно, чтобы использовать метод положительного подкрепления в дрессировке собаки?
- Нужно ли использовать кликер?
- Как убедиться, что вы достаточно ЧАСТО применяете положительное подкрепление
- Но моя собака не пищевик!
- Какие аргументы приводят противники положительного подкрепления и почему эти аргументы несостоятельны?
- Шаг 7: Обучение рекуррентной нейросети
- Где применяется обучение с подкреплением – вдохновляющие примеры
- Обучение бота для игры в packman
- Обучение с подкреплением для манипуляторов роботов
- Для чего можно использовать положительное подкрепление?
- Идеи для систем жетонов
- Шаг 2: Решение
- Вариационный автоэнкодер (VAE)
- Контроллер
- Диалог
- Почему положительное подкрепление не работает?
- Шаг 10: Обучение «в воображении»
- Обучение с подкреплением: две основные цели обучения
- Какую еду мне нужно использовать в качестве подкрепления?
- Но тренер говорит, что это не применимо к моей собаке?!
- Обязательно ли делать жетоны из предметов? Мой ученик слишком большой/у него слишком развитые навыки, и жетоны выглядят как-то по-детски.
- Какое условное подкрепление использовать: слово-маркер или кликер?
- Зачем нам нужно условное подкрепление?
- Описание груши сорта Яковлевская
- Зачем использовать позитивное подкрепление в обучении собак?
- Эффективное применение положительного подкрепления для детей всех возрастов
Что нужно, чтобы использовать метод положительного подкрепления в дрессировке собаки?
Метод положительного подкрепления можно применять со всеми собаками, так что от собаки требуется лишь достаточно здоровья, чтобы быть в состоянии учиться вообще и освоить те или иные навыки, в частности.
От человека, который принял решение использовать в обучении собаки положительное подкрепление, требуется:
- Понимание, что является поощрением для конкретной собаки «здесь и сейчас».
- Определение точного момента поощрения. Если, обучая собаку садиться по команде, вы поощряете ее, когда она встает, то вы научите ее вставать, а не сидеть.
- Терпение. Иногда необходимо дать собаке возможность подумать.
- Последовательность. В жизни собаки должны быть правила, а поведение владельца должно быть предсказуемым. Если вы сегодня пользуетесь положительным подкреплением, а завтра используете удавку или бьете собаку током, она не будет знать, чего от вас ожидать – это подорвет доверие к вам, и успеха вы вряд ли добьетесь.
Нужно ли использовать кликер?
Это решать вам.
Кликер используют, чтобы отметить момент, когда собака совершает правильное поведение. Это очень быстро, поэтому он дает вам возможно отсрочить момент дачи собаке лакомства (не в ту же секунду, а несколько секунд спустя).
Некоторым людям очень нравится пользоваться кликером
Они также считают, что это помогает улучшить их технику (возможно потому, что они уделяют пристальное внимание тому, когда нужно щелкнуть, и не двигаются до этого)
Некоторым людям не нравится кликер. Они находят его неуклюжим и неудобным или слишком сложным. К счастью для них, есть исследование, которое обнаружило, что для успешного обучения нет разницы в использовании кликера, вербального маркера или отсутствии маркера (только лакомства).
Для поведения, которое очень быстрое и мимолетное, маркер (клик или ваш голос) действительно поможет. Но для многих других команд, которым мы обучаем собаку, например, сидеть или лежать, вполне можно обойтись только лакомством.
Самое главное — это использовать пищевое подкрепление для обучения вашей собаки. Если вы попробуете кликер, возможно, вам понравится им пользоваться. Но если вам он не подойдет, не беспокойтесь об этом. Просто продолжайте использовать лакомство.
Как убедиться, что вы достаточно ЧАСТО применяете положительное подкрепление
Одна из причин того, почему я решила написать эту статью, в том, что я виновна в недостаточно частой похвале. Арестуйте меня! Эх! Я так на себя зла. Но, наверное, принятие — это первый шаг. Мои оправдания: я слишком занята, в классе вечно что-то происходит, дети по потолку ходят, за поведенческими планами не уследишь, тьюторы от рук отбились… Я знаю, просто оправдания. Так что я начала делать осознанные усилия, чтобы гарантировать, что я достаточно хвалю детей.
Сколько похвалы будет достаточно? На этот счет существуют разные теории. Я слышала о 6 положительных фразах в минуту во время работы с одним ребенком. Мне кажется, что это уже чересчур и может привести к речевой перегрузке ребенка. Я также слышала о коэффициенте 4:1 — на каждое негативное замечание должно приходиться четыре случая похвалы. Сами решайте, что вам подходит. Понять, когда положительное подкрепление эффективно, легче легкого — ваше любимое желательное поведение сохраняется и учащается, а не уменьшается!
Но моя собака не пищевик!
Это то, что каждому тренеру приходится выслушивать время от времени. Если это действительно так и ваша собака не заинтересована в еде, вам следует отвезти ее к ветеринару. Если ваша собака не ест, у нее может быть какая-то медицинская проблема, требующая обследования и лечения.
Чаще, когда люди говорят об этом, оказывается, что еда, которую они используют, не особо мотивирует собаку. Например, они предлагают ей гранулы сухого корма, которые она и так получает 2 раза в день — этого может быть недостаточно для мотивации собаки.
Это распространенная ошибка людей, которые новички в дрессировке. Если это относится к вам, проверьте список выше, чтобы найти там некоторые варианты лакомств. Скорее всего вам придется перепробовать несколько вариантов, чтобы узнать, какие больше нравятся вашей собаке, и помните, что разнообразие тоже может помочь.
Иногда люди неохотно используют еду для обучения собак, и именно поэтому используют сухой корм. Некоторые люди беспокоятся, что это может повлиять на их отношения с собакой — возможно, они боятся, что их собака на самом деле не любит их, если нужно использовать еду, чтобы она слушалась. Но ваша собака может любить и вас и еду, есть даже исследование фМРТ, доказывающее это.
А когда вы видите счастливый ожидающий взгляд вашей собаки, когда она хочет получить печенье, разве это не наполняет вас прекрасными теплыми чувствами?
Какие аргументы приводят противники положительного подкрепления и почему эти аргументы несостоятельны?
У положительного подкрепления есть и сторонники, и противники. Основные аргументы против использования исключительно положительного подкрепления:
- «Положительное подкрепление – это подкуп собаки».
- «Положительное подкрепление не формирует стабильный навык».
- «Положительное подкрепление – это вседозволенность».
Однако ни один из этих аргументов не является хоть сколько-нибудь состоятельным.
Если говорить о подкупе, то противники положительного подкрепления подменяют понятия. Подкуп – это когда вы показываете собаке лакомство или игрушку и подзываете. Да, во время обучения, чтобы собака поняла, что от нее требуется, мы, безусловно, учим ее подбегать на вкусный кусочек или игрушку – но только на этапе объяснения. А если вы позвали собаку, не подманивая ее, похвалили в момент, когда она отвернулась от других собак или от интересных запахов в траве и побежала к вам, а когда подбежала, играете с ней или угощаете – это не подкуп, а оплата.
Так что о подкупе речь точно не идет.
Те, кто говорят «Мы пробовали положительное подкрепление, но оно не формирует стабильный навык», вероятно, допускали ошибки в дрессировке собак. И одна из таких ошибок – резкое усложнение задачи.
Прежде чем переходить к следующему этапу, нужно убедиться в том, что собака понимает задачу. Если задачу усложнять постепенно, не пропускать важные этапы обучения и правильно выбирать способ мотивации, собака будет показывать отличный результат при обучении методом положительного подкрепления, причем стабильно.
К тому же, в положительном подкреплении используется метод «вариативного подкрепления», когда награда выдается не каждый раз, и собака не знает, получит ли она бонус за выполнение команды. Вариативное подкрепление более действенно, чем выдача приза после каждой команды. Разумеется, этот способ используется, когда навык уже сформирован, и собака точно понимает, чего вы от нее хотите. Это тоже обеспечивает стабильность выполнения команд.
Еще один аргумент противников положительного подкрепления – это «вседозволенность». «Собака сядет на шею!» — возмущаются они. Но вседозволенность – это когда владелец не вмешивается в поведение собаки, и она делает что хочет (хочет – ловит кошек, хочет – грызет обувь и т.п.) Однако, используя положительное подкрепление, мы обучаем собаку, объясняем правила совместного проживания и помогаем приспособиться к разумным ограничениям, подсказывая, каким образом она может удовлетворить свои потребности – просто делаем это гуманно. То есть с вседозволенностью положительное подкрепление тоже не имеет ничего общего.







Шаг 7: Обучение рекуррентной нейросети
Для обучения RNN требуется только и . Убедитесь, что вы успешно выполнили шаг 6, и файлы находятся в папке .
В командной строке выполните:
python 04_train_rnn.py --start_batch 0 --max_batch 9 --new_model
Это запустит процессы обучения новых RNN для каждого пакета данных от 0 до 9.
Веса модели будут сохранены в . Флаг сообщает скрипту, что модель нужно подготавливать с нуля.
Аналогично VAE, если в этой папке существуют, а флаг не указан, скрипт загрузит веса из этого файла и продолжит тренировку существующей модели. Аналогично это позволяет итеративно обучать RNN партиями.
Спецификация архитектуры RNN находится в файле .
Где применяется обучение с подкреплением – вдохновляющие примеры
Обучение с подкреплением применяется там, где нужно соизмерить отсроченную выгоду – цель – с ситуативным принятием решения. Этот вид обучения решает сложную задачу соотнесения немедленных действий с отсроченной отдачей, которую они производят. Как и людям, алгоритмам подкрепления обучения иногда приходится ждать, чтобы увидеть плоды своих решений. В таких случах зачастую сложно понять, какое действие приводит к какому результату.
Области практического применения reinforcement learning:
-
- Постановка целей
- Планирование
- Системы восприятия
- Боты для компьютерных игр
- Трейдинговые боты
- Чат боты, которые учатся от диалога к диалогу
Давайте посмотрим описания и видео нескольких вдохновляющих примеров.
Обучение бота для игры в packman
На видео ниже вы можете посмотреть результат бота, обученного по игре в Packman. Цель обучения – максимизировать набранные очки, при этом избегать “опасности” и, как следствие, проигрыша.
https://youtube.com/watch?v=QilHGSYbjDQ
Обучение с подкреплением для манипуляторов роботов
На следующем видео можно увидеть, как робот учится открывать дверь. Если вы не связаны с робототехникой, вам может быть не до конца понятно почему нельзя просто запрограммировать алгоритм “тяни или толкай”. Но в конце видео приводится пояснение зачем нужны такие сложности. В случае если, например, дверь держат с той стороны, или непонятно, надо тянуть дверь на себя или толкать от себя, “простой” алгоритм не будет работать. А алгоритм, основанный на нейронной сети, обученной методом с подкреплением, будет.
https://youtube.com/watch?v=ZhsEKTo7V04
Для чего можно использовать положительное подкрепление?
В свое время Э. Торндайк сформулировал «Закон Эффекта», согласно которому в одной и той же ситуации при прочих равных условиях лучше закрепляются те реакции, которые привели к чувству удовлетворения. Также идею о связи поведения с последствиями разрабатывал основатель оперантного научения Б.Ф. Скиннер.
Метод положительного подкрепления основан на том, что поведение, которое подкрепляется, проявляется все чаще. И главный его плюс в том, что удовлетворяется мотивация собаки.
Причем положительное подкрепление не имеет ограничений в сфере использования. То есть мы можем использовать его, чтобы научить собаку (как и любое животное, в принципе способное обучаться) чему угодно и даже чтобы скорректировать проблемное поведение.
![]()
![]()
Идеи для систем жетонов
— Приклейте наклейки со смайликами на игровые фишки, прикрепите их к любой поверхности с помощью ленты-«липучки».
— Заламинируйте наклейки с персонажами из любимого мультфильма ребенка. Заламинируйте сцену из мультфильма из детской раскраски или журнала. Прикрепите к ней жетоны с помощью ленты-«липучки». Например, ученик может зарабатывать жетоны с «Паровозиком Томасом» и прикреплять их на рельсы. Когда он соберет весь поезд, он сможет получить отсроченное поощрение.
— Используйте буквы из игры «Эрудит» или буквы на магнитах, из которых можно составить имя ребенка. Когда ребенок заработает все буквы и сможет сложить свое имя, то он сможет получить отсроченное поощрение.
— На бумаге или белой доске нарисуйте нужное количество клеточек для букв в названии поощрения (например, 7 клеточек для «попкорн»). Каждый раз, когда ученик правильно отвечает, пишите в клеточке одну букву.
— Сфотографируйте и увеличьте фотографию поощрения. Распечатайте и заламинируйте фотографию. Разрежьте ее на части (или приклейте фотографию на картон или «пенку», а потом разрежьте ее наподобие паззла). Давайте один кусочек изображения за один верный ответ. Когда ребенок соберет всю картинку, он получит то, что на ней изображено.
— Сделайте две копии страницы из раскраски с любимыми персонажами ребенка. На одной копии раскрасьте фон, но персонажей оставьте черно-белыми. Закрасьте персонажей на другой странице, вырежьте их и разрежьте на части, заламинируйте и прикрепите на них ленту-«липучку». За желательное поведение награждайте ребенка раскрашенной частью, которую можно прикрепить к черно-белому изображению. Когда весь рисунок будет готов, ребенок сможет получить поощрение.
— Используйте несколько маленьких ковриков. Положите их в линию между ребенком и поощрением. При каждом верном ответе ребенок сможет делать один шаг к поощрению.
— Если у ребенка есть любимый паззл, давайте ему кусочек паззла за каждый верный ответ. Когда паззл будет собран, ребенок получит доступ к отсроченному поощрению.
![Результаты поиска по запросу «[обучение с подкреплением]» / хабр](https://psy-files.ru/wp-content/uploads/f/d/2/fd2a696213c19cfe5330771df34df8bd.jpg)







— Используйте доску для колышков, выдавая один колышек за каждый правильный ответ. Когда доска будет заполнена, ребенок получит доступ к отсроченному поощрению.
— Используйте монетки в качестве награды, назначая «цену» за отсроченное поощрение и позволяя ученику «купить» его.
— Используйте настольную игру, где нужно передвигать фишки или фигурки до финишной черты. За каждый правильный ответ передвигайте фишку на одну клетку вперед. На финише помещается поощрение или его фотография.
— Поместите на стол две стеклянные банки. Наполните одну из них стеклянными шариками, на другую банку приклейте изображение поощрения. За желательное поведение или правильные ответы перекладывайте шарики из одной банки в другую. Когда вторая банка будет наполнена, ученики смогут получить доступ к поощрению.
— Используйте в качестве жетонов части самого поощрения. Например, за каждый правильный ответ вручайте рельсы для игрушечной железной дороги. Когда вся дорога будет проложена, ребенок сможет играть в поезда.
Подходите к процессу творчески и учитывайте интересы ребенка при разработке системы жетонов. Главное, не забывайте веселиться!
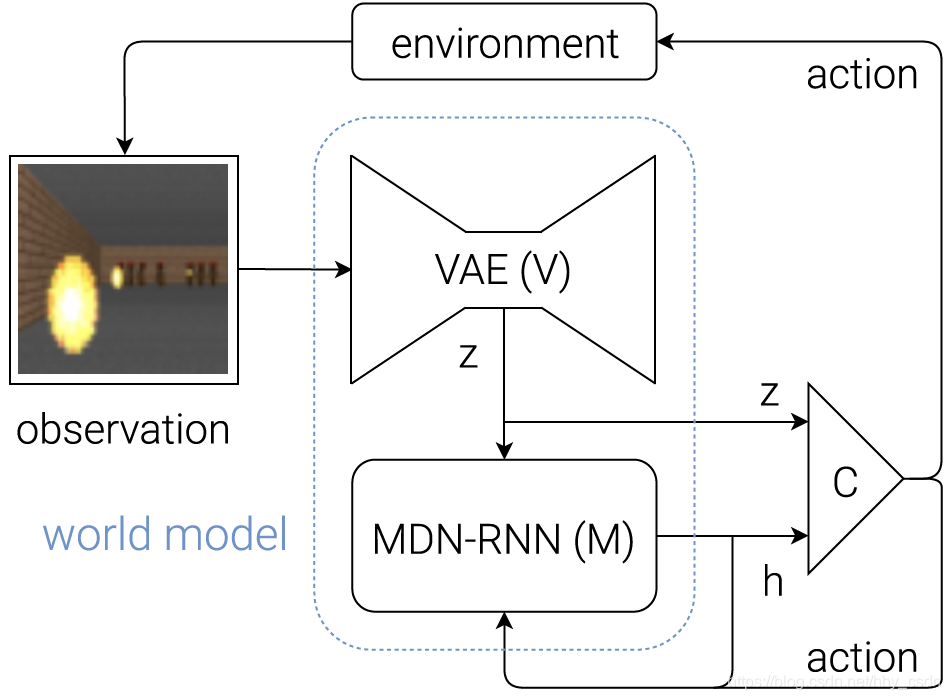
Шаг 2: Решение
Авторы представили отличное интерактивное объяснение своей методологии, поэтому не будем вдаваться в подробности, а лучше сосредоточимся на кратком обзоре того, как части решения взаимодействуют друг с другом, и проведем аналогию с реальным вождением, чтобы объяснить интуитивный смысл.
Решение состоит из трех отдельных частей, которые обучаются отдельно:
Вариационный автоэнкодер (VAE)
В процессе вождения машины вы не будете активно анализировать каждый «пиксель» того, что видите. Вместо этого ваш мозг превращает визуальную информацию в меньшее количество «скрытых» признаков, таких как прямолинейность дороги, предстоящие изгибы и позицию относительно дороги, чтобы подумать и сообщить о следующем действии.
Это именно то, чему обучается VAE — сжимать входное изображение 64x64x3 (RGB) в 32-мерный скрытый вектор z, удовлетворяющий нормальному распределению.
Такое представление визуального окружения полезно, т.к. гораздо меньше по размеру, и агент может обучаться эффективнее.
Рекуррентная нейронная сеть с сетью смеси распределений на выходе (Recurrent Neural Network with Mixture Density Network output, MDN-RNN)
Если в принятии решений вы обходитесь без компонента MDN-RNN, ваше вождение может выглядеть примерно так. Когда вы едете на машине, каждое последующее наблюдение не является для вас полной неожиданностью. Вы знаете, что если в данный момент окружение предполагает поворот налево на дороге, и вы поворачиваете колеса влево, вы ожидаете, что следующий кадр покажет, что вы все еще на одной линии с дорогой.
Подобное мышление наперед — суть работы RNN, сети долгой краткосрочной памяти (LSTM) с 256 скрытыми значениями. Вектор скрытых состояний обозначим за h.
Подобно VAE, RNN пытается зафиксировать внутреннее «понимание» текущего состояния автомобиля в своем окружении, но на этот раз с целью предсказать, как будет выглядеть последующий z на основе предыдущего z и совершённого действия.
Выходной слой MDN просто учитывает тот факт, что следующий z может быть фактически выведен из любого из нескольких нормальных распределений.
![]() MDN для генерации почерка
MDN для генерации почерка
Тот же автор применил данный метод в этой статье для задачи генерации почерка, чтобы описать тот факт, что следующая точка пера может оказаться в любой из красных отдельных областей.
Аналогично, в статье «Модели мира» следующее наблюдаемое скрытое состояние может быть составлено из любого из пяти гауссовских распределений.
Контроллер
До этого момента мы ничего не говорили о выборе действия. Эта ответственность лежит на Контроллере.
Контроллер — это обычная полносвязная нейронная сеть, где вход представляет собой конкатенацию z (текущее скрытое состояние от VAE, длина 32) и h (скрытое состояние RNN, длина 256). 3 выходных нейрона соответствуют трем действиям, их значения масштабируются для попадания в соответствующие диапазоны.
Диалог
Чтобы понять разные роли трех компонентов и то, как они работают вместе, можно представить себе своеобразный диалог между ними:
VAE: (смотрит последнее наблюдение размера 64 * 64 * 3) “Это выглядит как прямая дорога, с легким левым поворотом, приближающимся к машине, движущейся вдоль дороги”.
RNN: “Из того, что мне описал VAE (вектор z) и того факта, что Контроллер решил ускориться на последнем шаге, я обновлю свое скрытое состояние (h), чтобы предсказание следующего наблюдения все еще была прямая дорога, но с чуть более сильным левым поворотом”.
Контроллер: “На основании описания из VAE (z) и текущего скрытого состояния из RNN (h) моя нейронная сеть выводит следующее действие как ”.
Затем это действие передается в окружение, которая возвращает новое наблюдение, и цикл повторяется снова.
Теперь мы рассмотрим, как настроить среду, которая позволяет вам обучать собственную версию агента для автогонок.
Пора писать код!
Почему положительное подкрепление не работает?
Если вы думаете: «Я попробовал положительное подкрепление, и это не сработало!», то для этого есть несколько возможных причин.
Возможно, наиболее распространенной причиной является использование неподходящей награды, чтобы мотивировать собаку. Вернитесь к списку лакомств, и подберите что-нибудь повкуснее.









Но есть и ряд других возможных причин.
Возможно, вы не планируете занятия. Вы получите лучшие результаты, если будете составлять план занятий и следовать ему.
Возможно, вы недостаточно быстро даете лакомство. Например, вы просите собаку лечь, но к тому моменту, когда вы достанете лакомство, она уже вскочила, так что вы вознаградили неправильное поведение. Вам нужно научиться давать награду, как можно быстрее вслед за нужным поведением.
Может быть, наоборот, зная, что вам нужно как можно быстрее вознаградить собаку, вы на самом деле перемещаете свою руку к сумке с лакомством прежде, чем собака выполнит команду. Это может ее запутать. Собака реагирует на движение вашей руки как на подсказку.
Или, может быть, вы дали собаке слишком сложное задание. Очень часто кажется, что собака уже научилась нужному поведению после нескольких повторов. Это как если бы вы учились танцевать вальс, разучивая движения, но несколько удачных попыток недостаточно, чтобы научиться вальсировать; это требует больше практики. Ваша собака точно также нуждается в большей практике.
![]() И, говоря о практике, вы также должны очень медленно вводить отвлекающие стимулы. Просто потому, что ваша собака умеет выполнять команду сидеть в комнате, когда ничего интересного вокруг не происходит, не означает, что она сможет так же выполнить ее в парке, когда рядом бегают другие собаки или дети, или даже белка. Это очень сложно!
И, говоря о практике, вы также должны очень медленно вводить отвлекающие стимулы. Просто потому, что ваша собака умеет выполнять команду сидеть в комнате, когда ничего интересного вокруг не происходит, не означает, что она сможет так же выполнить ее в парке, когда рядом бегают другие собаки или дети, или даже белка. Это очень сложно!
Это все, над чем вы можете работать, но дрессировка собак — это сложное мастерство, и вам нечего стыдиться, если у вас не получается. Вам может потребоваться обратиться за помощью к квалифицированному тренеру собак или записаться в группу дрессировки. Поскольку дрессировка собак не регулируется, убедитесь, что тренер, к которому вы хотите обратиться, не использует аверсивные методы, а работает на положительном подкреплении.
Также вы можете воспользоваться списком литературы и интернет-ресурсов, которые я рекомендую.
Шаг 10: Обучение «в воображении»
Уже увиденнные нами вещи довольно круты, но следующая часть статьи просто потрясает мозг, и, полагаю, может серьезно повлиять на развитие ИИ.
Далее в статье описываются другие удивительные результаты, на основе другой среды DoomTakeCover. Здесь цель состоит в том, чтобы перемещать агента, избегать огненных шаров и оставаться в живых как можно дольше.
Агент действительно способен научиться играть в игру в своем собственном «воображении», построенном VAE/RNN, а не внутри самой окружающей среды.
Единственное обязательное дополнение состоит в том, что RNN обучается также прогнозировать вероятность быть убитым на следующем шаге. Таким образом, комбинация VAE/RNN может быть обернута как самостоятельная среда и использоваться для обучения Контроллера. Это и есть концепция «Моделей мира».
Мы могли бы описать обучение с воображением следующим образом:
- Первоначальные данные обучения агента представляют собой не что иное, как случайное взаимодействие с реальной средой. Благодаря этому он создает скрытое понимание того, как мир «работает» — его естественные признаки, физика и то, как собственные действия агента влияют на состояние мира.
- Затем он может использовать это понимание, чтобы установить оптимальную стратегию для поставленной задачи, не проверяя при этом ее в реальном мире. Эта проверка не требуется потому, что агент может использовать свою собственную внутреннюю, скрытую модель окружающей среды как «игровую площадку» для того, чтобы попытаться разобраться в том, что происходит.
Можно провести сравнение с ребенком, учащимся ходить — поразительные сходства! Возможно, это глубже, чем просто аналогия, что делает задачу по-настоящему увлекательной областью исследований.
Обучение с подкреплением: две основные цели обучения
Например, на дороге – в случае с беспилотным автомобилем. В обучении беспилотных автомобилей у машины нет задачи запомнить подробную карту города, страны, континента, все улицы и повороты. Но она обязательно должна понять шаблоны повторяющихся ситуаций и обобщить их.
Первая цель робота в обучении с подкреплением – минимизировать ошибки. Машина учится анализировать информацию перед каждым следующим ходом. Например, беспилотный автомобиль во время обучения учится вовремя реагировать на сигнал светофора, остановиться перед пешеходом на переходе, пропустить быстро движущийся автомобиль или спецтранспорт справа. Чтобы достичь лучшего результата, машина обучается в виртуальной модели города со случайными пешеходами и другими участниками дорожного движения.
Вторая цель робота в Reinforcement learning – получить от выполнения задания максимальную выгоду. Сама выгода при этом должна быть запрограммирована заранее: максимально быстрое время прохождения маршрута, оптимальное расходование ресурсов предприятия, обслуживание как можно большего количества посетителей.
Какую еду мне нужно использовать в качестве подкрепления?
Существует огромное разнообразие вариантов, начиная от лакомств, которые вы можете купить в зоомагазине, до человеческой пищи, которая подходит для собак, и лакомств, которые вы можете сделать сами.
Выберете то, что действительно нравится вашей собаке, потому что это будет лучше мотивировать ее. Конечно, лакомство должно вписываться в общую сбалансированную диету. Вы также можете менять лакомства, чтобы обеспечить разнообразие или выбрать подходящее для конкретного задания.
Например, если вы много тренируетесь, маленькие кубики отварной курицы могут быть наиболее подходящим выбором, потому что это здоровый компонент диеты собаки. Или вы можете использовать крошечные лакомства, чтобы не перекармливать собаку (особенно это касается маленьких собак). В других случаях кусочки сыра или мясных деликатесов могут быть подходящим вариантом в умеренных количествах. Используйте самые вкусные награды для обучению сложным навыкам, например, подзыву.
Вот примеры еды, которые вы можете использовать для подкрепления: кусочки курицы, вареной говядины, кубики сыра, сушеные лакомства из субпродуктов и рыбы, морковь, арахисовое масло, тунец, покупные лакомства из зоомагазина, сосиски, колбаса (не жирная!), ветчина и т.д.
Некоторые из этих продуктов вызвали у вас обильное выделение слюны? Это хорошо, потому что этот тот эффект, которого вы хотите добиться у своей собаки! Конечно, вы не используете целую сосиску сразу. Лакомство должно быть размером с горошину. Попробуйте несколько вариантов лакомств, чтобы узнать, что предпочитает ваша собака.
В качестве награды также может использоваться паштет из тюбика. Вы можете купить готовые (например, leanlix или Lickety Stik) или сделать свой собственный с помощью пластиковых тюбиков.
Как известно, кошек нельзя кормить собачьей едой, однако собакам кошачий корм не навредит, к тому же многие собаки любят более соленые кусочки сухого кошачьего корма.
Если вы покупаете лакомство в зоомагазине — прочитайте список ингредиентов, чтобы удостовериться, что оно подойдет вашей собаке.
Убедитесь, что лакомство безопасно для собаки
Если вы используете человеческую еду для поощрения, обратите внимание, чтобы в составе не было лука (может содержаться в некоторых мясных и других продуктах) и ксилита (например, в некоторых марках арахисового масла), которые не безопасны для собак
Если вы предпочитаете делать собственные лакомства, в интернете есть множество рецептов по их приготовлению. К тому же многие ингредиенты в них взаимозаменяемы.


![Результаты поиска по запросу «[обучение с подкреплением]» / хабр](https://psy-files.ru/wp-content/uploads/9/1/1/911d62d60b2b97a4cd1c1731e919039e.png)






Но тренер говорит, что это не применимо к моей собаке?!
Некоторые дрессировщики утверждают, что «положительное подкрепление не работает» или «это не сработает для вашей собаки» в качестве попытки оправдать использование ЭШО, строгого ошейника или удавки (контроллера).
Прежде всего помните, что дрессировка собак не регулируется. Некоторые тренеры просто не умеют работать иными способами, и поэтому считают неэффективным положительное подкрепление. Кроме того, старая традиционная школа дрессировки, представители которой все еще часто встречаются среди тренеров, считает, что собаки не способны к самоконтролю и пониманию того, что от них требуется, иначе, кроме как с помощью рывков и давления.
Во-вторых, важно знать, что существуют риски при использовании электрошоковых ошейников. Одно исследование в Великобритании показало, что ЭШО не более эффективны, чем положительное подкрепление для обучения собак подзыву
Они также обнаружили негативные последствия для благополучия некоторых собак.
Позаботьтесь о своей собаке и не позволяйте тренеру использовать методы дрессировки, которые вам не нравятся.
Обязательно ли делать жетоны из предметов? Мой ученик слишком большой/у него слишком развитые навыки, и жетоны выглядят как-то по-детски.
Практически что угодно можно использовать в качестве жетонов, которые потом обмениваются на отсроченное поощрение. Это могут быть кубики, стеклянные шарики или обычные «галочки» на бумаге. Если вам кажется, что ученик слишком взрослый для «смайликов» или плашки с жетонами, то вы можете использовать канцелярские скрепки на бумаге, фишки для покера, любые другие маленькие предметы.
Если вам нужна система поощрения в школьном классе, то можно приблизить ее к реальной жизни и использовать (игрушечные) купюры в качестве жетонов, чтобы ученики потом «платили» за отсроченные поощрения. Если вы хотите поработать над обобщением математических навыков в реальной жизни, то ученики могут вести тетрадь приходов и расходов, чтобы отслеживать количество своих жетонов.
Если вы можете доверить ученику добавление жетонов самому себе, то вы сможете ввести систему мониторинга за своим поведением. Так вам не только не придется тратить время на выдачу жетона, но ребенок будет учиться самостоятельно управлять своим собственным поведением. (Подробнее об управлении своим поведением смотрите в «Как управление собственным поведением может помочь при аутизме»).
Какое условное подкрепление использовать: слово-маркер или кликер?
Каждый выбирает тот вариант условного подкрепления, который удобнее лично ему. И кликер, и слово-маркер имеют свои преимущества.
|
Кликер в качестве условного подкрепления |
Слово-маркер как условное подкрепление |
|
Короткий, быстрый щелчок, максимально точно указывает на нужное действие. |
Необходим вдох, а значит, вы немного проигрываете в скорости и можете запоздать с подкреплением нужного действия. |
|
Щелчок всегда звучит одинаково. |
Интонации меняются. Это может быть как плюсом, так и минусом – в зависимости от ситуации. |
|
Необходимо носить с собой. |
Всегда наготове. |
|
Требует некоторой предварительной тренировки, чтобы научиться точно маркировать нужное действие. |
Если вы используете слово-маркер, оно может быть любым, но главное, чтобы оно было коротким.
Некоторые предпочитают выбирать такое слово, которое не используется в обычной жизни, чтобы не смущать собаку, но этот пункт не обязателен.
Зачем нам нужно условное подкрепление?
Значение условного подкрепления в дрессировке собаки переоценить сложно. Ведь когда собака поймет, что за щелчком кликера обязательно последует что-то замечательное, она начнет прислушиваться и следить за нашими действиями.
Введение в дрессировку собак условного подкрепления позволило совершить огромный прорыв, так как оно открывает много возможностей:
- Очень точно указать на то поведение, которое нам нужно. Произнести слово «Да!» или щелкнуть кликером – гораздо быстрее, чем лезть в карман за печеньем или доставать игрушку.
- Собаке легче понять, что от нее требуется, а человеку проще объяснять.
- Можно работать с собакой на расстоянии. Ведь пока вы добежите до собаки с лакомством, она совершит еще десяток действий и совершенно не поймет, за что ее поощрили. А маркер поможет точно показать, что именно вы покупаете.
Описание груши сорта Яковлевская
Хотя Розовоцветные являются самыми популярными плодовыми деревьями на территории европейской части постсоветского пространства, настоящих зимних сортов груши не так уж и много. Дело в том, что культуре, для нормального вызревания и накопления сахаров, необходимо определённое количество солнечных дней.
Недостаток солнца начинает ощущаться примерно на широте северной границе Украины. Можно сказать, что до недавнего времени, на большей части средней полосы России и всей территории Белоруссии, настоящих зимних сортов груши, отличающихся хорошей лёжкостью, было очень мало.
Ситуацию решили исправить специалисты одного из ведущих учреждений в области генетики и селекции, ВНИИГ и СПР им. И. В. Мичурина, расположенной в г. Мичуринске Тамбовской области. За основу были взяты сорта Толгарская красавица и Дочь Зари.









Результатом работ стало выведение нескольких новых родственных сортов, имеющих, в то же время, свои индивидуальные особенности: Ника, Феерия, Яковлевская. В работах над Яковлевской непосредственное участие принимали селекционеры С.П. Яковлев, В.В. Чивилев, Н.И. Савельев, А.П. Грибановский.
Годом рождения, а точнее регистрации сорта, считается 2002, когда его включили в Госреестр, и рекомендовали к разведению в следующих областях:
- Белгородская;
- Воронежская;
- Курская;
- Липецкая;
- Орловская;
- Тамбовская.
https://youtube.com/watch?v=XsuSf7zFrrg
Зачем использовать позитивное подкрепление в обучении собак?
Многие исследования показывают, что люди, которые используют методы обучения на основе положительного подкрепления, описывают своих собаках, как более послушных, чем те, кто применяет аверсивные методы. Использование положительного подкрепления улучшает контакт с собакой и лучше влияет на ее благополучие, чем использование отрицательного подкрепления. Корме того, предыдущий опыт обучения на положительном подкреплении, связан с лучшими успехами в обучении новому поведению.
Напротив, использование наказания, связано с агрессивной реакцией у некоторых собак, а использование аверсивных методов является фактором риска развития агрессии как по отношению к членам семьи, так и к посторонним.
Хотя эти исследования являются корреляционными и не доказывают причинности, есть несколько вещей, которые могут объяснить это. Во-первых, положительное подкрепление учит вашу собаку делать, а не просто наказывает за поведение (что совершенно не учит их новому поведению).
Другой момент, что наказание может являться стрессом для собаки, и если она свяжет владельца как причину наказания, это может негативно отразиться на отношениях с владельцем.
Есть еще одна причина использовать положительное подкрепление: собаки любят работать, чтобы зарабатывать награду. И теперь ученые рекомендуют, что для лучшего благополучия животных им необходим положительный опыт.
Поэтому использование положительного подкрепления в обучении полезно для вашей собаки.
Эффективное применение положительного подкрепления для детей всех возрастов
Для того, чтобы использовать устную похвалу как эффективное положительное подкрепление, она должна быть:
— Конкретной. Сделайте вашу похвалу максимально эффективной, конкретизировав, кого вы хвалите и за что именно! «Джереми, спасибо, что положил свою домашнюю работу в папку сделанных заданий. Это было просто здорово». Некоторые дети могут не понять, к чему относятся более общие фразы, и ваша попытка положительного подкрепления окажется напрасной!
— Незамедлительной. Начинайте хвалить сразу же после желательного поведения!
— Частой. Следите за тем, чтобы часто хвалить каждого ученика! Самая распространенная ошибка — слишком редкая похвала! Один раз в день — это слишком мало, продолжайте хвалить все виды желательного поведения, чтобы их сохранить!



